Collecting data to train HDF5 (Hierarchical Data Format), Data model, library, and file format for storing and managing large and complex data collections. HDF5 Files are commonly referred to as h5 files due to that being the file extension. H5 files are commonly used in scientific applications and are compatible with TensorFlow.
Before we begin collecting data via using web scraping, it is a good idea to check the potential targets terms of service to make sure everything is ethical. It is also a good idea to use time delays between scraped pages so the target website is not overwhelmed.
With that said, let’s scrape some training data.
The first steps to begin scraping is going to be setting up the environment by requesting required modules using the “pip” command. It is sometimes a good idea to repeat the dependency check
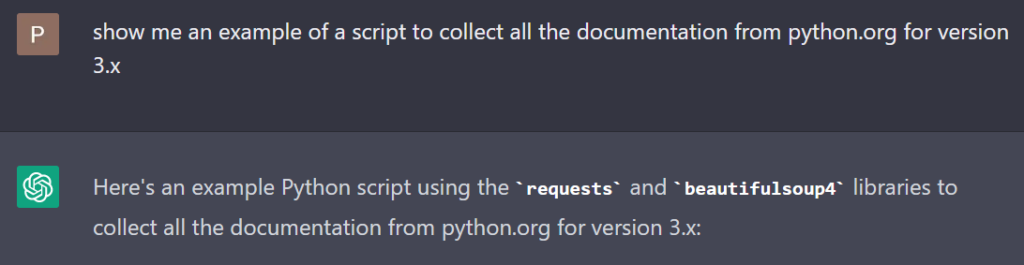
import requests
from bs4 import BeautifulSoup
import os
url = "https://docs.python.org/3/"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
links = []
for link in soup.find_all("a"):
href = link.get("href")
if href and href.startswith("https://docs.python.org/3/"):
links.append(href)
if not os.path.exists("python_docs"):
os.mkdir("python_docs")
for link in links:
filename = link.split("/")[-1]
response = requests.get(link)
with open(f"python_docs/{filename}", "wb") as f:
f.write(response.content)
This script starts by making a request to the URL for the Python 3 documentation on python.org. It then uses the BeautifulSoup library to parse the HTML content of the response.
The script looks for all the links on the page that point to another page on the same domain ("https://docs.python.org/3/"). It then creates a directory called python_docs (if it doesn’t already exist) and downloads each page to a file in that directory using the requests library. The filename for each page is based on the last part of the URL.
Note that this script will download all the pages linked to from the Python 3 documentation landing page (https://docs.python.org/3/). Depending on your internet connection speed, this may take some time and consume a significant amount of disk space.
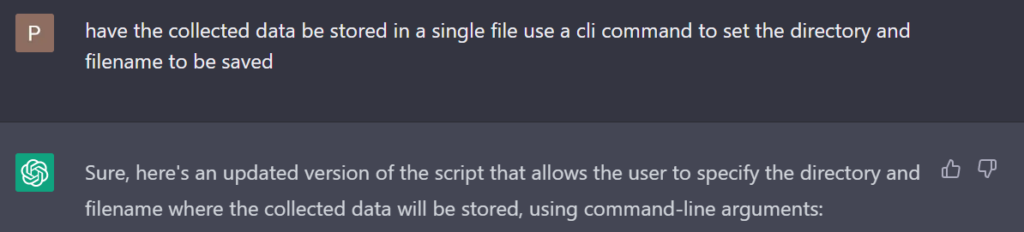
This updated script uses the argparse module to parse command-line arguments. The user must provide a required argument output_file, which is the path and filename where the collected data will be saved. The optional argument url specifies the URL to start collecting data from, defaulting to https://docs.python.org/3/.
To run the script and specify the output file, open a command prompt or terminal window, navigate to the directory where the script is saved, and run the script using the following command:
python collect_python_docs.py output_file_name --url https://docs.python.org/3/Replace output_file_name with the desired path and filename for the collected data.
The --url argument is optional, and can be used to specify a different starting URL if desired. It defaults to the Python3 documentation if the “–url” argument is not used.
The collected data will be saved to the specified output file. If the file already exists, its contents will be overwritten.
The last step is be setting up the environment by requesting required modules using the “pip” command. It is the last request from Open AI Chat, since you need the finalized script to gather the requirements.
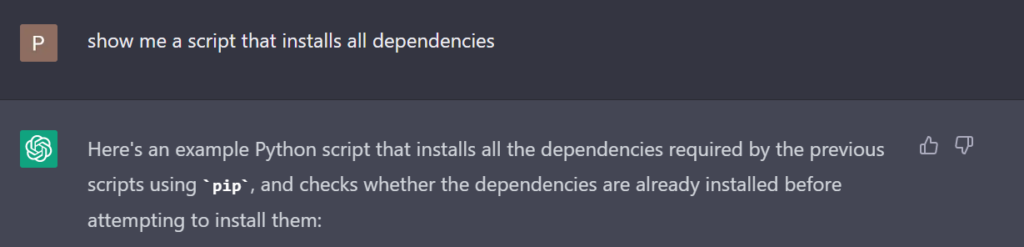
import subprocess
import sys
def install_dependencies():
dependencies = ["requests", "beautifulsoup4"]
for dependency in dependencies:
try:
subprocess.check_call([sys.executable, "-m", "install", dependency])
print(f"{dependency} has been installed.")
except subprocess.CalledProcessError as e:
print(f"Error installing {dependency}: {e}.")
else:
print(f"{dependency} is already installed.")
if __name__ == '__main__':
install_dependencies()
This script defines a function install_dependencies() that uses the subprocess module to execute a pip install command, installing the required requests and beautifulsoup4 packages. The command is executed using the same Python executable that is currently running, to ensure that the packages are installed for the correct version of Python.
The script can be run directly from the command line using the following command:
python install_dependencies.pyThis will install the required dependencies. If the dependencies are already installed, this command will have no effect.